
深入检出 Redis 主从复制
一、概述
单机、单节点、单实例问题
- 单点故障
- 容量有限
- 压力

X 轴问题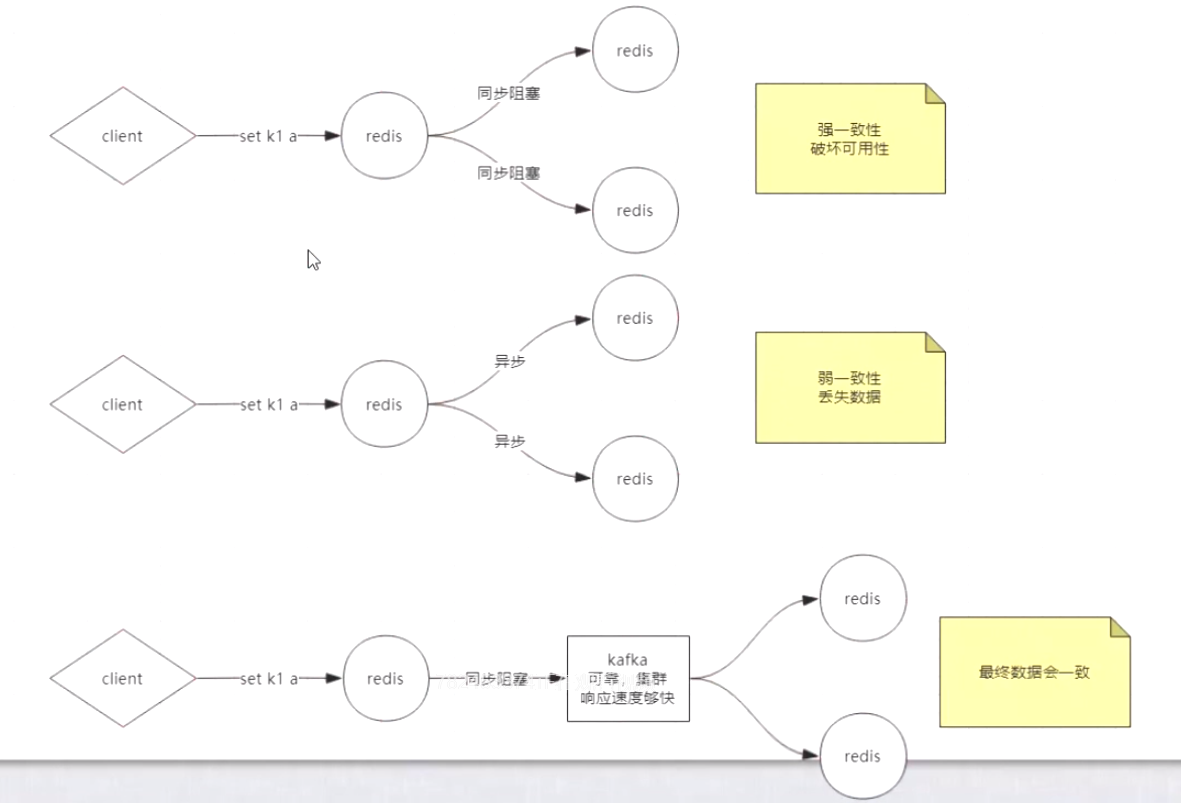
- 主备数据一致性
- 强一致性:降低可用性
- 最终一致性:使用可靠的速度快的消息队列集群
二、实现
info replication: 分片信息
1. 主从复制
replicaof: 5.0 以后
**slaveof:**5.0 以前
1 | # 成为 127.0.0.1 6379 的从节点 |
2. 取消主从复制
slaveof no one:
1 | slaveof no one |
3. 配置方式
3.1. 主节点配置
1 | port 6379 |
3.2. 从节点配置
1 | port 6380 |
三、主从链
避免复制风暴
随着负载不断上升,主服务器可能无法很快地更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。
为了解决这个问题,可以创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。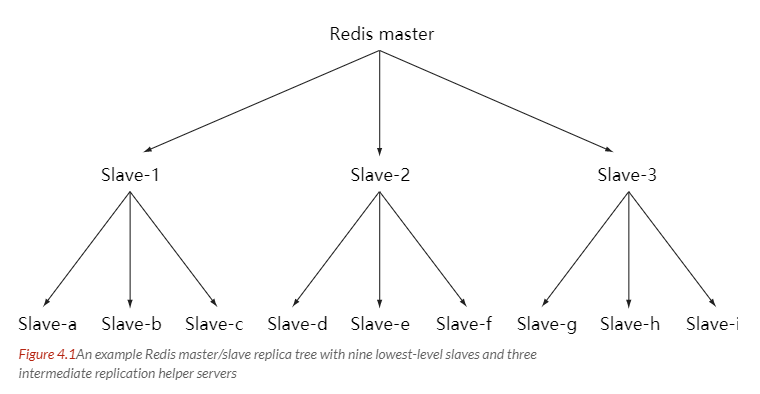
四、复制
1. 全量复制
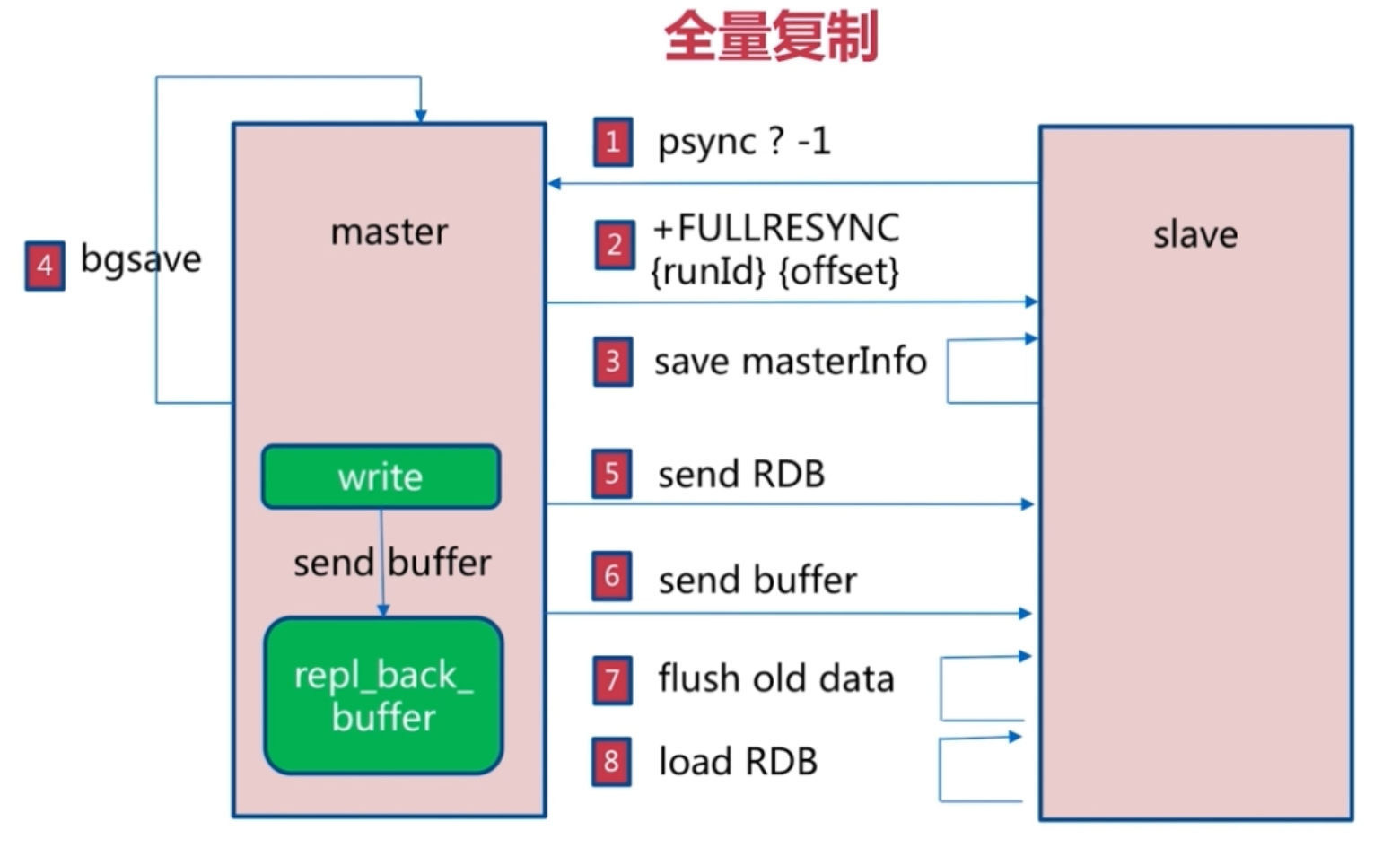
全量同步过程:
- 获取 runId 和 offset
- [1] slave 请求同步: slave 发送 psync runId offset 到 master 请求全量同步。由于不知道 master 的 runId 所以第一次请求发送 psync ? -1
- [2] master 返回信息: 返回 master 的 runId 和 offset
- [3] slave 保存信息
- 获取 RDB 文件 和 写命令
- _[4] master 持久化:_maset 异步执行 RDB 持久化(bgsave),同时把这之后执行的写命令加入缓冲区 repl_back_buffer
- [5] 发送 RDB 文件
- [6] 发送写命令
- 丢弃所有数据,载入 RDB 文件并执行写命令
- [7] 丢弃旧数据
- [8] 载入 RDB 文件和写命令
2. 部分复制

发送 pysnc runId offset 到 master 获取当前偏移量之后的数据