1. ThreadPoolExecutor 线程数计算公式: 线程数 = CPU 核数 * 期望 CPU 使用率 0~1_ *_(1 + 等待时间 / 计算时间)
1.1. 七大参数 1 2 3 4 ThreadPoolExecutor tpe = new ThreadPoolExecutor (2 , 4 , 60 , TimeUnit.SECONDS, new ArrayBlockingQueue <>(4 ), Executors.defaultThreadFactory(), new ThreadPoolExecutor .CallerRunsPolicy());
corePoolSize:核心线程数。保留在线程池中的线程数,即使它们处于空闲状态,除非设置了 allowCoreThreadTimeOut。
maximumPoolSize:最大线程数。线程池中允许的最大线程数,在阻塞队列满了之后加入的任务会创建非核心线程进行处理。
keepAliveTime:当线程数大于 corePoolSize 时,非核心线程在终止之前等待新任务的最大时间。
unit:keepAliveTime 参数的时间单位。
workQueue:阻塞队列。在执行任务之前用于保存任务的队列。 这个队列将只保存 execute 方法提交的 Runnable 任务。提交的线程后若发现线程总数超过 corePoolSize 但是不超过 keepAliveTime 的情况下。
threadFactory:用来执行的时候创建线程的线程工厂,可用于线程命名。
handler:在执行被阻塞时使用的处理程序,因为达到了线程边界和队列容量。
AbortPolicy:直接抛出异常,这是默认策略。
CallerRunsPolicy:用调用者所在的线程来执行任务。
DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务。
DiscardPolicy:直接丢弃任务。
随着任务不断增加
如果核心线程还没创建: 创建并执行任务。核心线程不会被销毁,会一直存在。
如果所有的核心线程都在执行任务: 把当前任务加入阻塞队列。
如果阻塞队列满了且线程数小于最大线程数: 创建非核心线程去执行。
如果阻塞队列满了且线程数满了,也都在执行任务: 进行拒绝策略。
1.2. API
execute (Runnable runnable):开启线程
shutdown ():会等待线程都执行完毕之后再关闭
shutdownNow ():相当于调用每个线程的 interrupt () 方法
submit ():如果只想中断 Executor 中的一个线程,可以通过使用 submit () 方法来提交一个线程,它会返回一个 Future<?> 对象,通过调用该对象的 cancel (true) 方法就可以中断线程。 1 2 3 4 Future<?> future = executorService.submit(() -> { }); future.cancel(true );
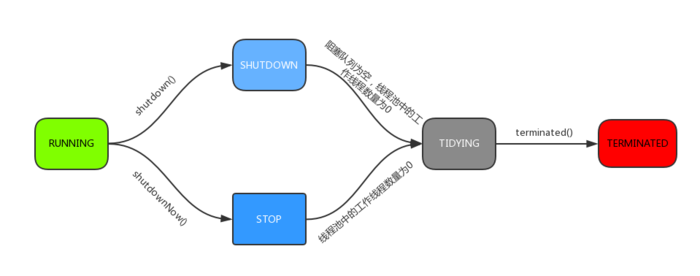
1.3. 线程池状态
RUNNING:能接受新提交的任务,并且也能处理阻塞队列中的任务
SHUTDOWN:关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。在线程池处于 RUNNING 状态时,调用 shutdown () 方法会使线程池进入到该状态。(finalize () 方法在执行过程中也会调用 shutdown () 方法进入该状态)
STOP:不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程。在线程池处于 RUNNING 或 SHUTDOWN 状态时,调用 shutdownNow () 方法会使线程池进入到该状态
TIDYING:如果所有的任务都已终止了,workerCount(有效线程数)为 0,线程池进入该状态后会调用 terminated () 方法进入 TERMINATED 状态
TERMINATED:在 terminated () 方法执行完后进入该状态,默认 terminated () 方法中什么也没有做
1.4. 源码 ctl: 高 3 位表示线程池状态,低 29 位表示 worker 数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 private final AtomicInteger ctl = new AtomicInteger (ctlOf(RUNNING, 0 ));private static final int COUNT_BITS = Integer.SIZE - 3 ;private static final int CAPACITY = (1 << COUNT_BITS) - 1 ;private static final int RUNNING = -1 << COUNT_BITS;private static final int SHUTDOWN = 0 << COUNT_BITS;private static final int STOP = 1 << COUNT_BITS;private static final int TIDYING = 2 << COUNT_BITS;private static final int TERMINATED = 3 << COUNT_BITS;private static int runStateOf (int c) { return c & ~CAPACITY; }private static int workerCountOf (int c) { return c & CAPACITY; }private static int ctlOf (int rs, int wc) { return rs | wc; }private static boolean runStateLessThan (int c, int s) { return c < s; } private static boolean runStateAtLeast (int c, int s) { return c >= s; }
execute (Runnable command) 方法:
worker 数量 <核心线程数 -> 直接创建 worker 执行任务
worker 数量 >= 核心线程数 && 线程池是运行状态 -> 任务直接进入队列
双重检查状态: 入队后再次检查状态,若线程池状态不是 RUNNING 状态,说明执行过 shutdown 命令,需要对新加入的任务执行 reject () 操作。核心线程数为 0 的情况: 若是 RUNNING 状态,且当前线程数为 0。该任务因核心线程数已满才加入阻塞队列,表明核心线程数为 0(在线程池构造方法中,核心线程数允许为 0)。这种情况会创建非核心线程去执行该任务
如果线程池不是运行状态,或者任务进入队列失败(例如队列满了),则尝试创建 worker 执行任务。如果创建 worker 失败,说明线程池 shutdown 或者饱和了,这时会执行拒绝。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public void execute (Runnable command) { if (command == null ) throw new NullPointerException (); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true )) return ; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0 ) addWorker(null , false ); } else if (!addWorker(command, false )) reject(command); }
addworker (Runnable firstTask, boolean core) 方法:
增加 worker 数量:使用两层自旋,第一层用于判断线程池状态,第二层使用 CAS 增加 worker 数量(CAS 自旋)
外层自旋:判断线程池状态。
状态 == RUNNING,通过
状态 == SHUTDOWN,任务为空且队列不为空,通过
其余情况返回 false
内层自旋:CAS 自旋
worker 数量超过容量,直接返回 false
使用 CAS 的方式增加 worker 数量。若成功则直接跳出整个外层自旋
否则重新获取状态,若状态发生变化,重新执行外层循环普判断状态
若状态没发生变化,意味着还可以继续竞争 CAS,直接继续内层循环
创建 worker 并执行
创建 Worker 对象 worker
加锁,把 worker 加入 workers(HashSet)
如果添加成功则调用 worker 内部线程的 start () 方法执行任务。实际上会执行 ThreadPoolExecutor#runWorker 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 private boolean addWorker (Runnable firstTask, boolean core) { retry: for (;;) { int c = ctl.get(); int rs = runStateOf(c); if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) return false ; for (;;) { int wc = workerCountOf(c); if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false ; if (compareAndIncrementWorkerCount(c)) break retry; c = ctl.get(); if (runStateOf(c) != rs) continue retry; } } boolean workerStarted = false ; boolean workerAdded = false ; Worker w = null ; try { w = new Worker (firstTask); final Thread t = w.thread; if (t != null ) { final ReentrantLock mainLock = this .mainLock; mainLock.lock(); try { int rs = runStateOf(ctl.get()); if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null )) { if (t.isAlive()) throw new IllegalThreadStateException (); workers.add(w); int s = workers.size(); if (s > largestPoolSize) largestPoolSize = s; workerAdded = true ; } } finally { mainLock.unlock(); } if (workerAdded) { t.start(); workerStarted = true ; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; }
Worker 类:
自身维护了一个 Thread thread (任务执行器)和一个 Runnable firstTask(任务)
在构造器中会把传入的任务赋值给 firstTask,然后把当前自己传入 thread
当调用 thread.start() 时会执行这个 worker 的 run () 方法,最终调用 ThreadPoolExecutor#runWorker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 private final class Worker extends AbstractQueuedSynchronizer implements Runnable { private static final long serialVersionUID = 6138294804551838833L ; final Thread thread; Runnable firstTask; volatile long completedTasks; Worker(Runnable firstTask) { setState(-1 ); this .firstTask = firstTask; this .thread = getThreadFactory().newThread(this ); } public void run () { runWorker(this ); } protected boolean tryAcquire (int unused) { if (compareAndSetState(0 , 1 )) { setExclusiveOwnerThread(Thread.currentThread()); return true ; } return false ; } ... }
runworker (Worker w):核心线程执行逻辑
如果 firstTask 不为 null,则执行 firstTask
如果 firstTask 为 null,则调用 getTask () 从队列获取任务执行
加锁 w.lock();。Worker 实现了 AQS,所以自己也是一把锁,并重写了 tryAcquire 方法(非重入)
判断写线程池状态,如果线程池正在停止,则对当前线程进行中断操作
执行任务 task.run();
已完成任务数加一 w.completedTasks++;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 final void runWorker (Worker w) { Thread wt = Thread.currentThread(); Runnable task = w.firstTask; w.firstTask = null ; w.unlock(); boolean completedAbruptly = true ; try { while (task != null || (task = getTask()) != null ) { w.lock(); if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) wt.interrupt(); try { beforeExecute(wt, task); Throwable thrown = null ; try { task.run(); } catch (RuntimeException x) { thrown = x; throw x; } catch (Error x) { thrown = x; throw x; } catch (Throwable x) { thrown = x; throw new Error (x); } finally { afterExecute(task, thrown); } } finally { task = null ; w.completedTasks++; w.unlock(); } } completedAbruptly = false ; } finally { processWorkerExit(w, completedAbruptly); } }
2. ForkJoinPool 概述:
Fork/Join 主要采用分而治之的理念来处理问题,对于一个比较大的任务,首先将它拆分 (fork) 为两个小任务 task1 与 task2。
原理:
ForkJoinPool 实现了工作窃取算法来提高 CPU 的利用率。每个线程都维护了一个双端队列,用来存储需要执行的任务。工作窃取算法允许空闲的线程从其它线程的双端队列中窃取一个任务来执行。
窃取的任务必须是最晚的任务,避免和队列所属线程发生竞争
2.1. RecursiveAction 不带返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class AddTask extends RecursiveAction { int start, end; AddTask(int s, int e) { start = s; end = e; } @Override protected void compute () { if (end - start <= MAX_NUM) { long sum = 0L ; for (int i = start; i < end; i++) { sum += nums[i]; } System.out.println("from:" + start + " to:" + end + " = " + sum); } else { int middle = start + (end - start) / 2 ; AddTask subTask1 = new AddTask (start, middle); AddTask subTask2 = new AddTask (middle, end); subTask1.fork(); subTask2.fork(); } } public static void main (String[] args) { ForkJoinPool fjp = new ForkJoinPool (); AddTask task = new AddTask (0 , nums.length); fjp.execute(task); } }
2.2. RecursiveTask 带返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class ForkJoinExample extends RecursiveTask <Integer> { private final int threshold = 5 ; private int first; private int last; public ForkJoinExample (int first, int last) { this .first = first; this .last = last; } @Override protected Integer compute () { int result = 0 ; if (last - first <= threshold) { for (int i = first; i <= last; i++) { result += i; } } else { int middle = first + (last - first) / 2 ; ForkJoinExample leftTask = new ForkJoinExample (first, middle); ForkJoinExample rightTask = new ForkJoinExample (middle + 1 , last); leftTask.fork(); rightTask.fork(); result = leftTask.join() + rightTask.join(); } return result; } public static void main (String[] args) throws ExecutionException, InterruptedException { ForkJoinExample example = new ForkJoinExample (1 , 10000 ); ForkJoinPool forkJoinPool = new ForkJoinPool (); Future result = forkJoinPool.submit(example); System.out.println(result.get()); } }
3. Executors
CachedThreadPool: 一个任务创建一个线程
1 2 3 4 5 6 7 public static void main (String[] args) { ExecutorService executorService = Executors.newCachedThreadPool(); for (int i = 0 ; i < 5 ; i++) { executorService.execute(new MyRunnable ()); } executorService.shutdown(); }
FixedThreadPool: 所有任务只能使用固定大小的线程
SingleThreadExecutor: 相当于大小为 1 的 FixedThreadPool
WorkStealingPool:工作窃取线程池
1 2 3 4 5 6 public static ExecutorService newWorkStealingPool () { return new ForkJoinPool (Runtime.getRuntime().availableProcessors(), ForkJoinPool.defaultForkJoinWorkerThreadFactory, null , true ); }