
Redis 从入门到入土②:数据类型与结构
1. 数据类型
| 数据类型 | 可以存储的值 | 应用场景 |
|---|---|---|
| STRING | 字符串、整数或者浮点数 | 计数(秒杀、点赞)、缓存 |
| LIST | 列表 | 消息队列、排行榜、关注列表 |
| SET | 无序集合 | 集群部署全局去重 共同喜好,自己独有的喜好 |
| ZSET | 有序集合 | 排行榜 |
| HASH | 包含键值对的无序散列表 | 单点登录,以 cookieId 作为 key 模拟 session、 存储对象 |
2. 使用场景
- 计数器
- 可以对 String 进行自增自减运算,从而实现计数器功能
- Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量
- 缓存
- 将热点数据放到内存中,设置内存的最大使用量以及淘汰策略来保证缓存的命中率
- 查找表
- 例如 DNS 记录就很适合使用 Redis 进行存储
- 查找表和缓存类似,也是利用了 Redis 快速的查找特性。但是查找表的内容不能失效,而缓存的内容可以失效,因为缓存不作为可靠的数据来源
- 消息队列
- List 是一个双向链表,可以通过 lpop 和 lpush 写入和读取消息。不过最好使用 Kafka、RabbitMQ 等消息中间件
- 会话缓存
- 可以使用 Redis 来统一存储多台应用服务器的会话信息
- 当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性
- 分布式锁实现
- 在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。可以使用 Reids 自带的 SETNX 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现
- 并发
- 在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用 redis 做一个缓冲操作,让请求先访问到 redis,而不是直接访问数据库
- 其它
- Set 可以实现交集、并集等操作,从而实现共同好友等功能
- ZSet 可以实现有序性操作,从而实现排行榜等功能
3. 数据结构
3.1. 字典
dictht 结构: dictht 是一个散列表结构,使用拉链法保存哈希冲突
1 | /* This is our hash table structure. Every dictionary has two of this as we |
dict rehash 操作:
Redis 的字典 dict 中包含两个哈希表 dictht,这是为了方便进行 rehash 操作
在扩容时,将其中一个 dictht 上的键值对 rehash 到另一个 dictht 上面,完成之后释放空间并交换两个 dictht 的角色
1 | typedef struct dict { |
渐进方式: rehash 操作不是一次性完成,而是采用渐进方式,这是为了避免一次性执行过多的 rehash 操作给服务器带来过大的负担
渐进式 rehash 通过记录 dict 的 rehashidx 完成,它从 0 开始,然后每执行一次 rehash 都会递增。例如在一次 rehash 中,要把 dict [0] rehash 到 dict [1],这一次会把 dict [0] 上 table [rehashidx] 的键值对 rehash 到 dict [1] 上,dict [0] 的 table [rehashidx] 指向 null,并令 rehashidx++
在 rehash 期间,每次对字典执行添加、删除、查找或者更新操作时,都会执行一次渐进式 rehash
采用渐进式 rehash 会导致字典中的数据分散在两个 dictht 上,因此对字典的查找操作也需要到对应的 dictht 去执行
1 | /* Performs N steps of incremental rehashing. Returns 1 if there are still |
3.2. 跳跃表
概述: 是有序集合的底层实现之一。跳跃表是基于多指针有序链表实现的,可以看成多个有序链表
查找: 在查找时,从上层指针开始查找,找到对应的区间之后再到下一层去查找。
下图演示了查找 22 的过程: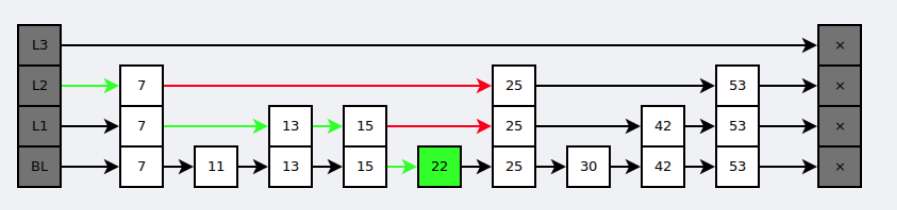
优点: 与红黑树等平衡树相比,跳跃表具有以下优点:
- 插入速度非常快速,因为不需要进行旋转等操作来维护平衡性
- 更容易实现
- 支持无锁操作
原理:
1 | /* ZSETs use a specialized version of Skiplists */ |
