
JVM 从入门到入土 ⑥:GC 调优
GC 日志
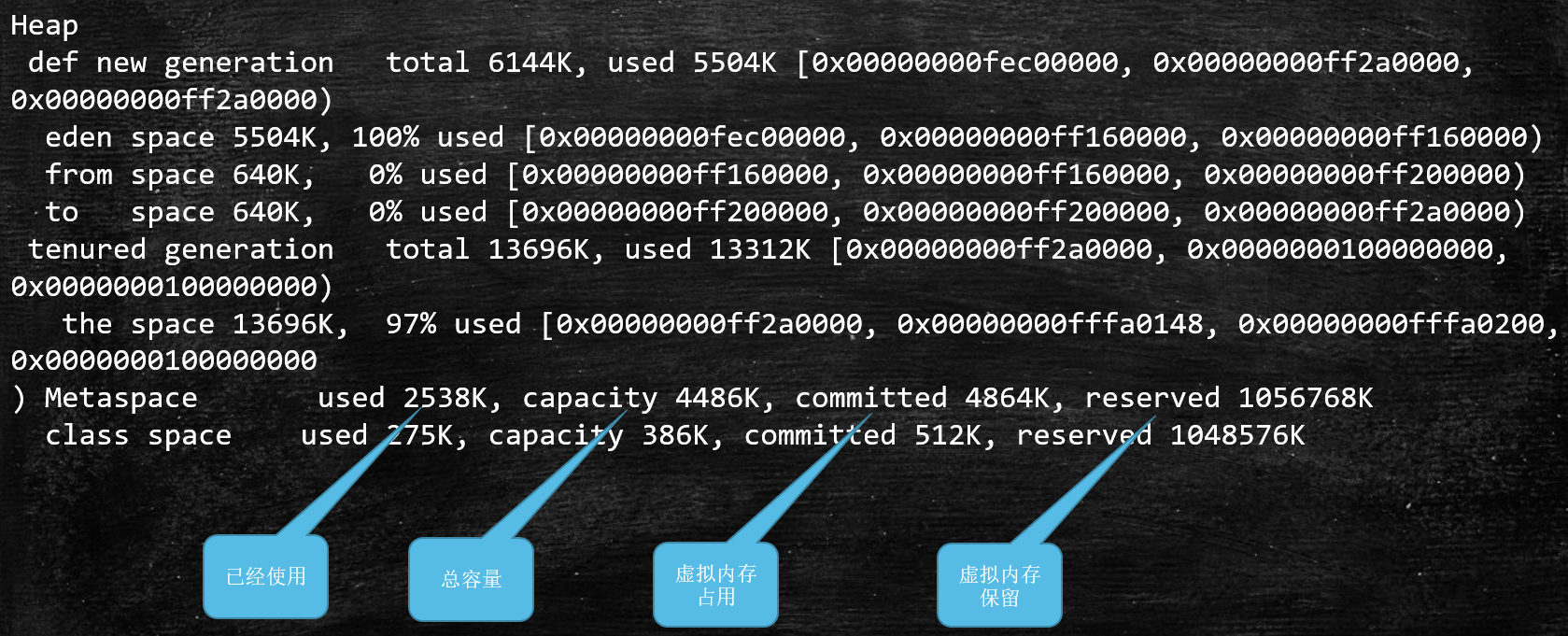
PS GC 日志详解
PS 日志格式:
heap dump 部分:
1 | eden space 5632K, 94% used [0x00000000ff980000,0x00000000ffeb3e28,0x00000000fff00000) |
CMS 日志分析
执行命令:java -Xms20M -Xmx20M -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC com.mashibing.jvm.gc.T15_FullGC_Problem01
[GC (Allocation Failure) [ParNew: 6144K->640K(6144K), 0.0265885 secs] 6585K->2770K(19840K), 0.0268035 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
ParNew:年轻代收集器
6144->640:收集前后的对比
(6144):整个年轻代容量
6585 -> 2770:整个堆的情况
(19840):整个堆大小
1 | [GC (CMS Initial Mark) [1 CMS-initial-mark: 8511K(13696K)] 9866K(19840K), 0.0040321 secs] [Times: user=0.01 sys=0.00, real=0.00 secs] |
G1 日志详解
1 | [GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.0015790 secs] |
GC 调优
基础概念
- 吞吐量:用户代码时间 /(用户代码执行时间 + 垃圾回收时间)
- 响应时间:STW 越短,响应时间越好
所谓调优,首先确定,追求啥?吞吐量优先,还是响应时间优先?还是在满足一定的响应时间的情况下,要求达到多大的吞吐量…
问题:
科学计算,吞吐量。数据挖掘,thrput。吞吐量优先的一般:(PS + PO)
响应时间:网站 GUI API (1.8 G1)
什么是调优?
- 根据需求进行 JVM 规划和预调优
- 优化运行 JVM 运行环境(慢,卡顿)
- 解决 JVM 运行过程中出现的各种问题(OOM)
调优规划
调优,从业务场景开始,没有业务场景的调优都是耍流氓
监控(压力测试,能看到结果)
步骤:
- 熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
- 响应时间、停顿时间 [CMS G1 ZGC] (需要给用户作响应)
- 吞吐量 = 用户时间 /(用户时间 + GC 时间) [PS]
- 选择回收器组合
- 计算内存需求(经验值 1.5G 16G)
- 选定 CPU(越高越好)
- 设定年代大小、升级年龄
- 设定日志参数
- -Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause
- 或者每天产生一个日志文件
- 观察日志情况
- 熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
案例 1:垂直电商,最高每日百万订单,处理订单系统需要什么样的服务器配置?
这个问题比较业余,因为很多不同的服务器配置都能支撑(1.5G 16G)
1 小时 360000 集中时间段, 100 个订单 / 秒,(找一小时内的高峰期,1000 订单 / 秒)
经验值,
非要计算:一个订单产生需要多少内存?512K * 1000 500M 内存
专业一点儿问法:要求响应时间 100ms
压测!案例 2:12306 遭遇春节大规模抢票应该如何支撑?
12306 应该是中国并发量最大的秒杀网站:
号称并发量 100W 最高
CDN -> LVS -> NGINX -> 业务系统 -> 每台机器 1W 并发(10K 问题) 100 台机器
普通电商订单 -> 下单 -> 订单系统(IO)减库存 -> 等待用户付款
12306 的一种可能的模型: 下单 -> 减库存 和 订单 (redis kafka) 同时异步进行 -> 等付款
减库存最后还会把压力压到一台服务器
可以做分布式本地库存 + 单独服务器做库存均衡
大流量的处理方法:分而治之怎么得到一个事务会消耗多少内存?
- 弄台机器,看能承受多少 TPS?是不是达到目标?扩容或调优,让它达到
- 用压测来确定
优化步骤
- 有一个 50 万 PV 的资料类网站(从磁盘提取文档到内存)原服务器 32 位,1.5G
的堆,用户反馈网站比较缓慢,因此公司决定升级,新的服务器为 64 位,16G
的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了- 为什么原网站慢?
很多用户浏览数据,很多数据 load 到内存,内存不足,频繁 GC,STW 长,响应时间变慢 - 为什么会更卡顿?
内存越大,FGC 时间越长 - 解决方案:PS -> PN + CMS 或者 G1
- 为什么原网站慢?
- 系统 CPU 经常 100%,如何调优?(面试高频)
CPU 100% 那么一定有线程在占用系统资源,- 找出哪个进程 cpu 高(top)
- 该进程中的哪个线程 cpu 高(top -Hp)
- 导出该线程的堆栈(jstack)
- 查找哪个方法(栈帧)消耗时间(jstack)
- 工作线程占比高 | 垃圾回收线程占比高
- 系统内存飙高,如何查找问题?(面试高频)
- 导出堆内存(jmap)
- 分析(jhat jvisualvm mat jprofiler … )
- 如何监控 JVM
- jstat jvisualvm jprofiler arthas top…
解决 JVM 运行中的问题
一个案例理解常用工具
测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49/**
* 从数据库中读取信用数据,套用模型,并把结果进行记录和传输
*/
public class T15_FullGC_Problem01 {
private static class CardInfo {
BigDecimal price = new BigDecimal(0.0);
String name = "张三";
int age = 5;
Date birthdate = new Date();
public void m() {}
}
private static ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(50,
new ThreadPoolExecutor.DiscardOldestPolicy());
public static void main(String[] args) throws Exception {
executor.setMaximumPoolSize(50);
for (;;){
modelFit();
Thread.sleep(100);
}
}
private static void modelFit(){
List<CardInfo> taskList = getAllCardInfo();
taskList.forEach(info -> {
// do something
executor.scheduleWithFixedDelay(() -> {
//do sth with info
info.m();
}, 2, 3, TimeUnit.SECONDS);
});
}
private static List<CardInfo> getAllCardInfo(){
List<CardInfo> taskList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
CardInfo ci = new CardInfo();
taskList.add(ci);
}
return taskList;
}
}java -Xms200M -Xmx200M -XX:+PrintGC com.mashibing.jvm.gc.T15_FullGC_Problem01
运维团队首先受到报警信息(CPU Memory)
top 命令观察到问题:内存不断增长 CPU 占用率居高不下
top -Hp 观察进程中的线程,哪个线程 CPU 和内存占比高
jps 定位具体 java 进程
jstack 定位线程状况,重点关注:WAITING BLOCKED
eg.
waiting on <0x0000000088ca3310> (a java.lang.Object)
假如有一个进程中 100 个线程,很多线程都在 waiting on,一定要找到是哪个线程持有这把锁
怎么找?搜索 jstack dump 的信息,找,看哪个线程持有这把锁 RUNNABLE 线程的名称(尤其是线程池)都要写有意义的名称
jinfo pid
jstat -gc 动态观察 gc 情况 / 阅读 GC 日志发现频繁 GC /arthas 观察 /jconsole/jvisualVM/ Jprofiler(最好用)
jstat -gc 4655 500 : 每个 500 个毫秒打印 GC 的情况
如果面试官问你是怎么定位 OOM 问题的?如果你回答用图形界面(错误)
1:已经上线的系统不用图形界面用什么?(cmdline arthas)
2:图形界面到底用在什么地方?测试!测试的时候进行监控!(压测观察)jmap - histo 4655 | head -20,查找有多少对象产生
jmap -dump:format=b,file=xxx pid :
线上系统,内存特别大,jmap 执行期间会对进程产生很大影响,甚至卡顿(电商不适合)
1:设定了参数 HeapDump,OOM 的时候会自动产生堆转储文件
2:很多服务器备份(高可用),停掉这台服务器对其他服务器不影响
3:在线定位(一般小点儿公司用不到)java -Xms20M -Xmx20M -XX:+UseParallelGC -XX:+HeapDumpOnOutOfMemoryError com.mashibing.jvm.gc.T15_FullGC_Problem01
使用 MAT /jhat/jvisualvm 进行 dump 文件分析
java 命令 –jhat 命令使用
jhat -J-mx512M xxx.dump
http://192.168.17.11:7000
拉到最后:找到对应链接
可以使用 OQL 查找特定问题对象找到代码的问题
jconsole 远程连接
程序启动加入参数:
1
java -Djava.rmi.server.hostname=192.168.17.11 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=11111 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false XXX
如果遭遇 Local host name unknown:XXX 的错误,修改 /etc/hosts 文件,把 XXX 加入进去
1
2192.168.17.11 basic localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6关闭 linux 防火墙(实战中应该打开对应端口)
1
2service iptables stop
chkconfig iptables off #永久关闭windows 上打开 jconsole 远程连接 192.168.17.11:11111
jvisualvm 远程连接
简单做法:使用 jvisualvm 的 jstatd 方式远程监控 Java 程序
jprofiler(收费)
arthas 在线排查工具
- 为什么需要在线排查?
在生产上我们经常会碰到一些不好排查的问题,例如线程安全问题,用最简单的 threaddump 或者 heapdump 不好查到问题原因。为了排查这些问题,有时我们会临时加一些日志,比如在一些关键的函数里打印出入参,然后重新打包发布,如果打了日志还是没找到问题,继续加日志,重新打包发布。对于上线流程复杂而且审核比较严的公司,从改代码到上线需要层层的流转,会大大影响问题排查的进度。 - jvm 观察 jvm 信息
- thread 定位线程问题
- dashboard 观察系统情况
- heapdump + jhat 分析
- jad 反编译
动态代理生成类的问题定位
第三方的类(观察代码)
版本问题(确定自己最新提交的版本是不是被使用) - redefine 热替换
目前有些限制条件:只能改方法实现(方法已经运行完成),不能改方法名, 不能改属性
m() -> mm() - sc - search class
- watch - watch method
- 没有包含的功能:jmap
产生原因案例
OOM 产生的原因多种多样,有些程序未必产生 OOM,不断 FGC(CPU 飙高,但内存回收特别少)(上面案例)
硬件升级系统反而卡顿的问题(见上)
线程池不当运用产生 OOM 问题(见上)
不断的往 List 里加对象(实在太 LOW)jira 问题
实际生产参数案例:1
2
3
4
5
6
7
8
9
10-Xms9216m -Xmx9216m
-XX:-OmitStackTraceInFastThrow
-Xloggc:/opt/xxx/logs/xxx-gc-%t.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=20M
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintGCCause -classpath /opt/xxx/bin/...jar
实际系统不断重启
解决问题 加内存 + 更换垃圾回收器 G1
真正问题在哪儿?不知道tomcat http-header-size 过大问题(Hector)
lambda 表达式导致方法区溢出问题(MethodArea / Perm Metaspace)
LambdaGC.java -XX:MaxMetaspaceSize=9M -XX:+PrintGCDetails1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41"C:\Program Files\Java\jdk1.8.0_181\bin\java.exe" -XX:MaxMetaspaceSize=9M -XX:+PrintGCDetails "-javaagent:C:\Program Files\JetBrains\IntelliJ IDEA Community Edition 2019.1\lib\idea_rt.jar=49316:C:\Program Files\JetBrains\IntelliJ IDEA Community Edition 2019.1\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_181\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\access-bridge-64.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\cldrdata.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\dnsns.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\jaccess.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\jfxrt.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\localedata.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\nashorn.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunec.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunjce_provider.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunmscapi.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunpkcs11.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\zipfs.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\javaws.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jce.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jfr.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jfxswt.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jsse.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\management-agent.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\plugin.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\resources.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\rt.jar;C:\work\ijprojects\JVM\out\production\JVM;C:\work\ijprojects\ObjectSize\out\artifacts\ObjectSize_jar\ObjectSize.jar" com.mashibing.jvm.gc.LambdaGC
[GC (Metadata GC Threshold) [PSYoungGen: 11341K->1880K(38400K)] 11341K->1888K(125952K), 0.0022190 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Metadata GC Threshold) [PSYoungGen: 1880K->0K(38400K)] [ParOldGen: 8K->1777K(35328K)] 1888K->1777K(73728K), [Metaspace: 8164K->8164K(1056768K)], 0.0100681 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
[GC (Last ditch collection) [PSYoungGen: 0K->0K(38400K)] 1777K->1777K(73728K), 0.0005698 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Last ditch collection) [PSYoungGen: 0K->0K(38400K)] [ParOldGen: 1777K->1629K(67584K)] 1777K->1629K(105984K), [Metaspace: 8164K->8156K(1056768K)], 0.0124299 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at sun.instrument.InstrumentationImpl.loadClassAndStartAgent(InstrumentationImpl.java:388)
at sun.instrument.InstrumentationImpl.loadClassAndCallAgentmain(InstrumentationImpl.java:411)
Caused by: java.lang.OutOfMemoryError: Compressed class space
at sun.misc.Unsafe.defineClass(Native Method)
at sun.reflect.ClassDefiner.defineClass(ClassDefiner.java:63)
at sun.reflect.MethodAccessorGenerator$1.run(MethodAccessorGenerator.java:399)
at sun.reflect.MethodAccessorGenerator$1.run(MethodAccessorGenerator.java:394)
at java.security.AccessController.doPrivileged(Native Method)
at sun.reflect.MethodAccessorGenerator.generate(MethodAccessorGenerator.java:393)
at sun.reflect.MethodAccessorGenerator.generateSerializationConstructor(MethodAccessorGenerator.java:112)
at sun.reflect.ReflectionFactory.generateConstructor(ReflectionFactory.java:398)
at sun.reflect.ReflectionFactory.newConstructorForSerialization(ReflectionFactory.java:360)
at java.io.ObjectStreamClass.getSerializableConstructor(ObjectStreamClass.java:1574)
at java.io.ObjectStreamClass.access$1500(ObjectStreamClass.java:79)
at java.io.ObjectStreamClass$3.run(ObjectStreamClass.java:519)
at java.io.ObjectStreamClass$3.run(ObjectStreamClass.java:494)
at java.security.AccessController.doPrivileged(Native Method)
at java.io.ObjectStreamClass.<init>(ObjectStreamClass.java:494)
at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:391)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1134)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348)
at javax.management.remote.rmi.RMIConnectorServer.encodeJRMPStub(RMIConnectorServer.java:727)
at javax.management.remote.rmi.RMIConnectorServer.encodeStub(RMIConnectorServer.java:719)
at javax.management.remote.rmi.RMIConnectorServer.encodeStubInAddress(RMIConnectorServer.java:690)
at javax.management.remote.rmi.RMIConnectorServer.start(RMIConnectorServer.java:439)
at sun.management.jmxremote.ConnectorBootstrap.startLocalConnectorServer(ConnectorBootstrap.java:550)
at sun.management.Agent.startLocalManagementAgent(Agent.java:137)直接内存溢出问题(少见)
《深入理解 Java 虚拟机》P59,使用 Unsafe 分配直接内存,或者使用 NIO 的问题栈溢出问题
-Xss 设定太小比较一下这两段程序的异同,分析哪一个是更优的写法:
1
2
3
4
5Object o = null;
for(int i=0; i<100; i++) {
o = new Object();
// 业务处理
}重写 finalize 引发频繁 GC
小米云,HBase 同步系统,系统通过 nginx 访问超时报警,最后排查,C++ 程序员重写 finalize 引发频繁 GC 问题
为什么 C++ 程序员会重写 finalize?(new delete)
finalize 耗时比较长(200ms)如果有一个系统,内存一直消耗不超过 10%,但是观察 GC 日志,发现 FGC 总是频繁产生,会是什么引起的?
System.gc () (这个比较 Low)Distuptor 有个可以设置链的长度,如果过大,然后对象大,消费完不主动释放,会溢出 (来自 死物风情)
用 jvm 都会溢出,mycat 用崩过,1.6.5 某个临时版本解析 sql 子查询算法有问题,9 个 exists 的联合 sql 就导致生成几百万的对象(来自 死物风情)
new 大量线程,会产生 native thread OOM,(low)应该用线程池,
解决方案:减少堆空间(太 TM low 了),预留更多内存产生 native thread
JVM 内存占物理内存比例 50% - 80%
GC 参数
JVM 的命令行参数参考
HotSpot 参数分类
- 标准: - 开头,所有的 HotSpot 都支持
- 非标准:-X 开头,特定版本 HotSpot 支持特定命令
- 不稳定:-XX 开头,下个版本可能取消
常用参数
- -Xmn -Xms -Xmx -Xss
年轻代 最小堆 最大堆 栈空间 - -XX:+UseTLAB
使用 TLAB,默认打开 - -XX:+PrintTLAB
打印 TLAB 的使用情况 - -XX:TLABSize
设置 TLAB 大小 - -XX:+DisableExplictGC
System.gc () 不管用 ,FGC - -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintHeapAtGC
- -XX:+PrintGCTimeStamps
- -XX:+PrintGCCauses
- -XX:+PrintGCApplicationConcurrentTime(低)
打印应用程序时间 - -XX:+PrintGCApplicationStoppedTime (低)
打印暂停时长 - -XX:+PrintReferenceGC (重要性低)
记录回收了多少种不同引用类型的引用 - -verbose:class
类加载详细过程 - -XX:+PrintVMOptions
- -XX:+PrintFlagsFinal
- -XX:+PrintFlagsInitial:查看所有 JVM 参数启动的初始值
- -XX:+PrintCommandLineFlags:默认的参数
- -Xloggc:opt/log/gc.log
- -XX:MaxTenuringThreshold
升代年龄,最大值 15 - 锁自旋次数 -XX:PreBlockSpin 热点代码检测参数 -XX:CompileThreshold 逃逸分析 标量替换 …
这些不建议设置
Parallel 常用参数
- -XX:SurvivorRatio
- -XX:PreTenureSizeThreshold
大对象到底多大 - -XX:MaxTenuringThreshold
- -XX:+ParallelGCThreads
并行收集器的线程数,同样适用于 CMS,一般设为和 CPU 核数相同 - -XX:+UseAdaptiveSizePolicy
自动选择各区大小比例
CMS 常用参数
- -XX:+UseConcMarkSweepGC
- -XX:ParallelCMSThreads
CMS 线程数量 - -XX:CMSInitiatingOccupancyFraction
使用多少比例的老年代后开始 CMS 收集,默认是 68%(近似值),如果频繁发生 SerialOld 卡顿,应该调小,(频繁 CMS 回收) - -XX:+UseCMSCompactAtFullCollection
在 FGC 时进行压缩 - -XX:CMSFullGCsBeforeCompaction
多少次 FGC 之后进行压缩 - -XX:+CMSClassUnloadingEnabled
- -XX:CMSInitiatingPermOccupancyFraction
达到什么比例时进行 Perm 回收 - GCTimeRatio
设置 GC 时间占用程序运行时间的百分比 - -XX:MaxGCPauseMillis
停顿时间,是一个建议时间,GC 会尝试用各种手段达到这个时间,比如减小年轻代
G1 常用参数
- -XX:+UseG1GC
- -XX:MaxGCPauseMillis
建议值,G1 会尝试调整 Young 区的块数来达到这个值 - -XX:GCPauseIntervalMillis
?GC 的间隔时间 - -XX:+G1HeapRegionSize
分区大小,建议逐渐增大该值,1 2 4 8 16 32。
随着 size 增加,垃圾的存活时间更长,GC 间隔更长,但每次 GC 的时间也会更长
ZGC 做了改进(动态区块大小) - G1NewSizePercent
新生代最小比例,默认为 5% - G1MaxNewSizePercent
新生代最大比例,默认为 60% - GCTimeRatio
GC 时间建议比例,G1 会根据这个值调整堆空间 - ConcGCThreads
线程数量 - InitiatingHeapOccupancyPercent
启动 G1 的堆空间占用比例
参考资料
- Our Collectors
- Java Platform, Standard Edition Tools Reference
- Java HotSpot VM Options
- JVM 调优参考文档: HotSpot Virtual Machine Garbage Collection Tuning Guide
- 利用 JVM 在线调试工具排查线上问题
- Arthas 使用:arthas 常用命令
- Arthas 手册:
- 启动 arthas java -jar arthas-boot.jar
- 绑定 java 进程
- dashboard 命令观察系统整体情况
- help 查看帮助
- help xx 查看具体命令帮助
- jmap 命令参考: https://www.jianshu.com/p/507f7e0cc3a3
- jmap -heap pid
- jmap -histo pid
- jmap -clstats pid