
ES 写入原理及调优
背景
ES 支持四种对文档的数据写操作:create、delete、index、update,这些对数据进行更改的操作的流程和原理是怎么样的呢?以及,了解写入原理对我们有什么帮助?
1. 解决写入问题
心心念念用上了 ES,但是却在项目中遇到写入并发问题及写入大吞吐量数据之类的问题,这时候需要好好了解下 ES 的写入原理,再结合项目实际情况对相关参数进行调优。
2. 学习架构设计思想
这也是很重要的一点,了解 ES 是如何处理写入中遇到的问题,以及这些处理方式是否在我们平常项目中有所帮助。
3. 应对面试
虽然比较功利,但不可否认,写入原理是 ES 面试的高频问题
常见的面试问题:
- 你了解 ES 的写入原理吗
- 你了解文档的写入 / 删除过程吗
- 如何保证 ES 数据写入一致性
- 文档写入超时原因
- ES 写入实时性如何去保证
- 数据量大时如何保证数据写入性能
- 如何提高数据检索能力
写入流程
ES 中的数据写入均发生在主分片上。由于 ES 是分布式系统,实际接收到写入请求的节点可能是任意一台节点,这就需要将请求通过 routing 路由到具体主分片所在的节点,将数据写入该节点的主分片中,然后主分片再同步数据到其他节点的副分片中。
路由公式:shard_num = hash(_routing) % num_primary_shards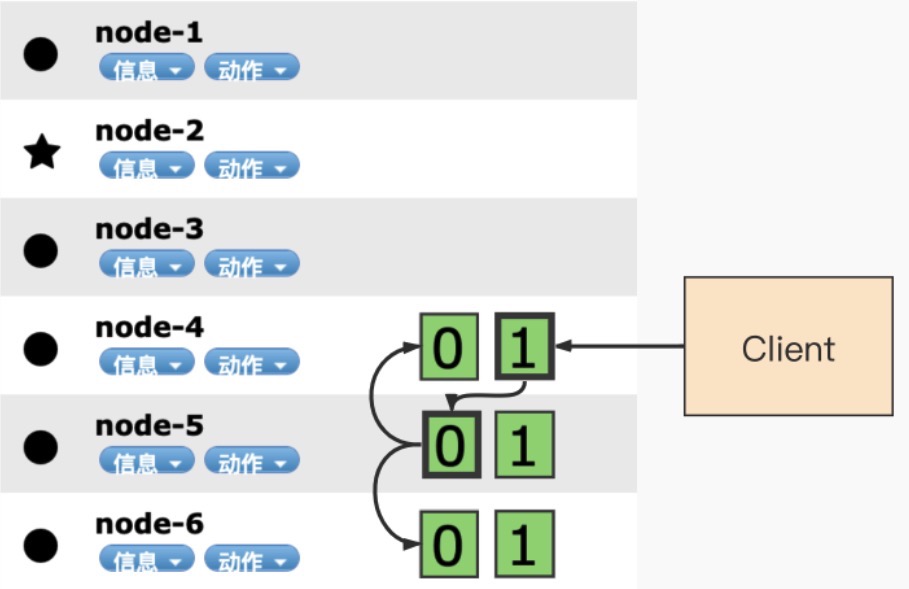
具体流程:
- 客户端发起写入请求至 node 4
- node 4 通过文档 id 在路由表中的映射信息确定当前数据的位置为分片 0,分片 0 的主分片位于 node 5,并将数据转发至 node 5。
- 数据在 node 5 写入,写入成功之后将数据的同步请求转发至其副本所在的 node 4 和 node 6 上面,等待所有副本数据写入成功之后 node 5 将结果报告 node 4,并由 node 4 将结果返回给客户端,报告数据写入成功。
写一致性策略
ES 5.x 之后,一致性策略由 wait_for_active_shards 参数控制:状态为 active 的主副分片数量达到设定阈值时才视为写入成功,才会返回数据给客户端。默认为 1,即只需要主分片写入成功,可设置为 all 或任何正整数,最大值为索引中的分片总数 ( number_of_replicas + 1 )。
如果当前 active 状态的副本没有达到设定阈值,写操作必须等待并且重试,默认等待时间 30 秒,直到 active 状态的副本数量超过设定的阈值或者超时返回失败为止。
执行索引操作时,分配给执行索引操作的主分片可能不可用。造成这种情况的原因可能是主分片当前正在从网关恢复或正在进行重定位。默认情况下,索引操作将在主分片上等待最多 1 分钟,然后才会失败并返回错误。
写入原理
我们已经知道了宏观上的写入流程:先找到主节点,写入主节点后再同步到副节点。
那 ES 是怎么把数据写入主节点和副节点中的呢?
大家可能会有疑问,难道不是直接写入到磁盘吗?我们可以思考下,每次请求都直接写入到磁盘这种方式在高并发的场景下会消耗大量的 IO 资源,每次都要寻址然后写入磁盘。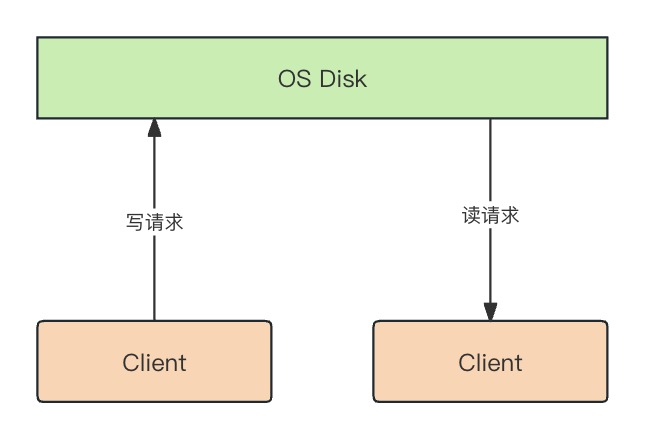
对此我们可以用缓存来解决,即把数据写入系统缓存后,定期批量写入磁盘,同时缓存也提供检索服务。
而 Lucene 中索引是细分为多个 segment 的,segment 是索引中存储索引数据的内部存储元素,并且是不可变的。较小的 segment 会定期合并到较大的 segment 中,以控制索引大小。问题又来了:如果每次请求都创建一个新的 segment,那么会导致频繁的合并操作(merge)。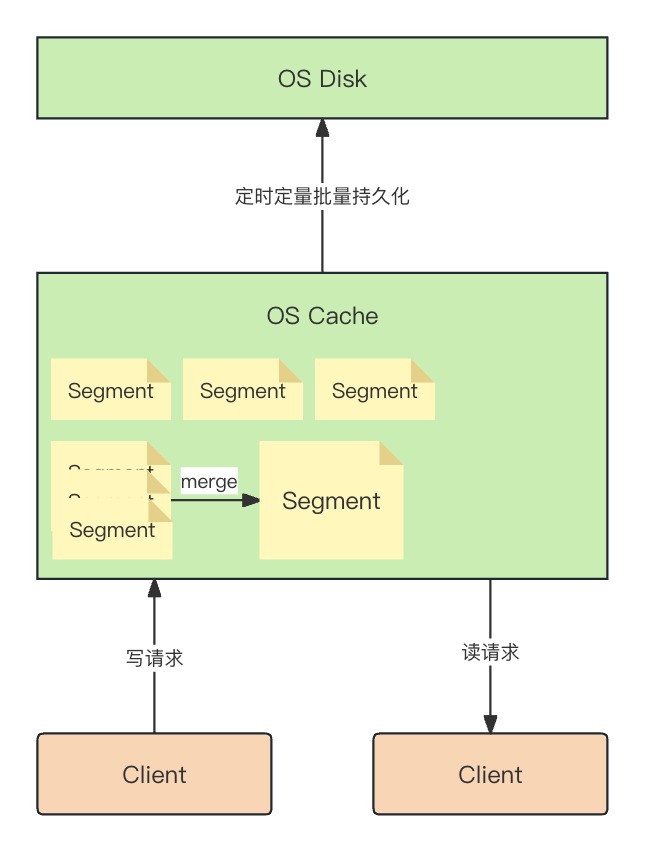
所以 ES 在请求进入缓存之前先让请求进缓冲区(memory buffer),每秒或每 100 个缓存才会执行刷新操作(Refresh)把缓冲区中的数据创建 segment 写入系统缓存中。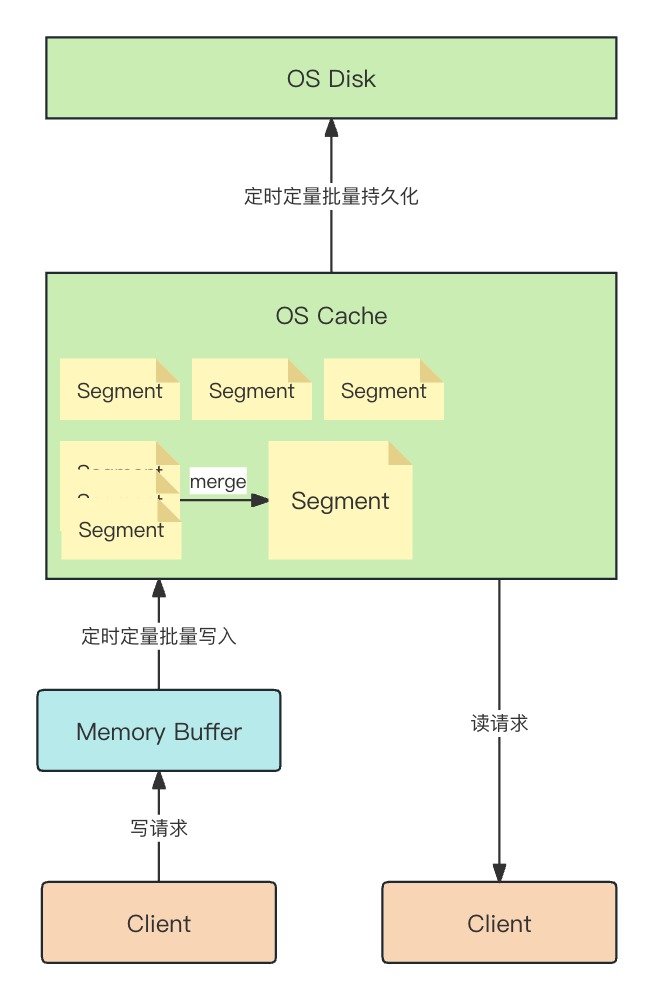
至此这套批量持久化结构已经比较完善,但还有一个问题:缓存虽然提高了性能,但毕竟未持久化到磁盘,一旦系统出现故障数据就会丢失。ES 采用事务日志(translog)的方式解决此问题,当请求进来时会同时写入缓冲区和事务日志中,当服务重启后就会从事务日志中恢复数据到缓存。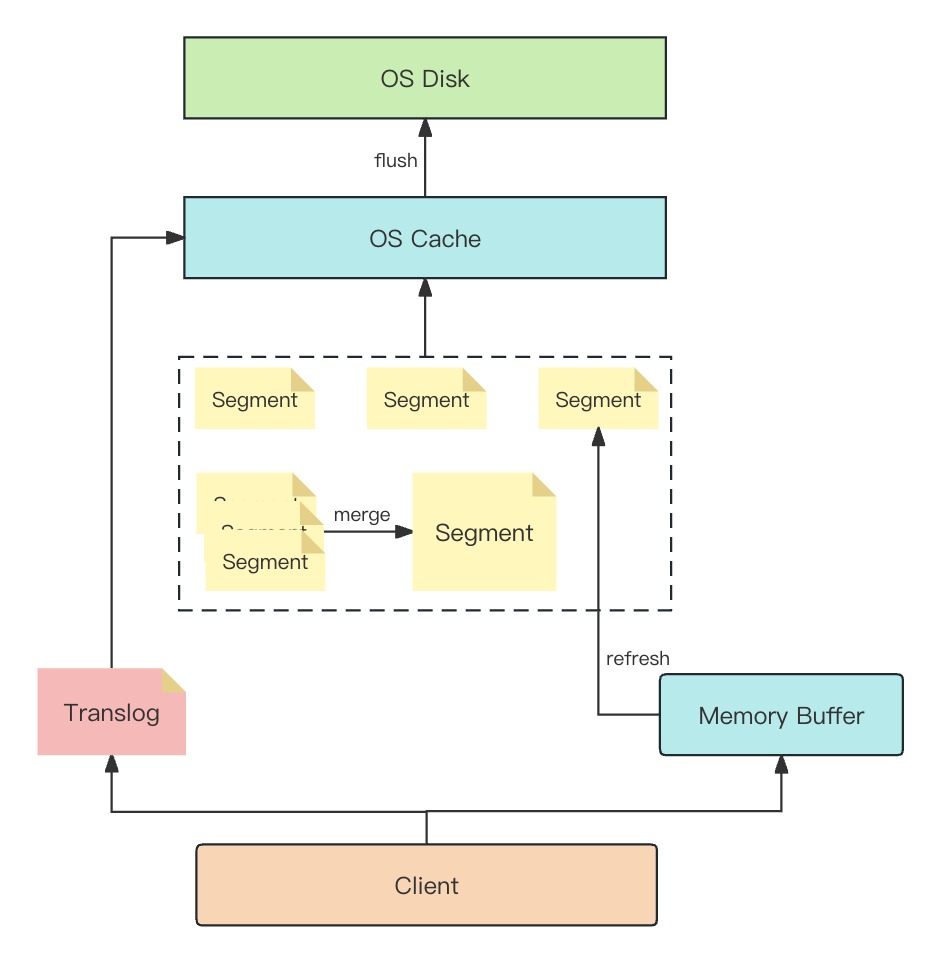
整体结构:
- Memory Buffer(缓冲区):数据批量操作,高性能写入
- Translog(事务日志):保证数据写入安全性,防止丢失
- OS Cache(内存):保证数据高性能检索
- OS Disk(磁盘):保证数据持久化
具体流程:
- 客户端写入 Memory Buffer 缓冲区,并追加写入 Translog 事务日志(删除、写入…)以保证数据安全性。
- Memory Buffer 达到阈值(100 条 / 1s)后执行 Refresh 操作生成 Segment 索引文件到系统缓存中。
- 然后系统缓存会把该 Segment 标记为可被检索,因此数据有 1s 不可读的延迟。
- Refresh 操作不能过于频繁,因此针对实时性不高的数据,可以配置 refresh 的间隔时间为 30s 一次。
- 每个 Segment 都会消耗文件句柄、内存、CPU 运行周期,所以每隔一段时间会执行 Merge 操作,合并 Segment。
- Merge 操作发生在 JVM 中,频率过高会占用堆内存空间,所以 Refresh 的频率不能太高,否则会使 Merge 频率增高。
- 不合并 Segment 的影响:
- 每个 Segment 占据的内存不会随着 GC 释放的。导致系统内存不足,进一步导致超时问题。
- 查询时会遍历每个 Segment,过多的 Segment 会导致查询速度下降。
- 执行 Flush 操作缓存写入 OS Disk(磁盘)并提交一次,并清空 Translog。
- 系统缓存每隔 30 分钟、Translog 每隔 5 秒刷一次到磁盘中,所以默认情况下,可能会有 5s 数据丢失。
- 系统缓存和 Translog 写满时也会刷磁盘。
- 断电等异常操作导致数据丢失时,服务重启后会读取 Translog 中的数据到缓存中,以完成回滚操作。
相关参数:
- index.translog.durability:同步还是异步
- request:(默认)主副分片在每个请求后执行 fsync 和 commit,才会向客户端报告索引、删除、更新或批量请求的成功。如果发生崩溃,那么所有只要是已经确认的写操作都已经被提交到磁盘。
- async:在后台每 index.translog.sync_interval 时间进行一次 fsync 和 commit。意味着如果发生崩溃,那么所有在上一次自动提交以后的已确认的写操作将会丢失。
- index.translog.sync_interval:translog 多久被同步到磁盘并提交一次。默认 5 秒。这个值不能小于 100ms。
- index.translog.flush_threshold_size:translog 执行 flush 操作的空间最大阈值,默认 512 MB。
写入性能调优
生产经常面临的写入可以分为两种情况:
- 高并发:高频的创建 / 更新索引文档,一般发生在 C 端场景下
- 高吞吐:定期重建索引或批量更新文档数据,一般为 B 端场景
1. 提升写入吞吐量和并发
ES 数据写入具有一定的延时性,这是为了减少频繁的索引文件产生。默认情况下 ES 每秒生成一个 segment 文件,当达到一定阈值的时候会执行 merge,merge 过程发生在 JVM 中,频繁的生成 segmen 文件可能会导致频繁的触发 FGC,导致 OOM。
为了避免避免这种情况,通常采取的手段是降低 segment 文件的生成频率,手段有两个,一个是增加时间阈值,另一个是增大 buffer 的空间阈值。
- 增加 flush 时间间隔。Flush 是 IO 操作,很消耗性能,不能太频繁
- 增加 refresh_interval 的参数值
- 目的是减少 segment 文件的创建,减少 segment 的 merge 次数。
- merge 是发生在 JVM 中的,有可能导致 full GC,增加 refresh 会降低搜索的实时性。
- 增加 buffer 大小
- 减小 refresh 的时间间隔,因为导致 segment 文件创建的原因不仅有时间阈值,还有 buffer 空间大小,写满了也会创建。
- 默认最小值 48MB < 默认值 JVM 空间的 10% < 默认最大无限制
- 关闭副本(提高单次吞吐)
- 需要单次写入大量数据的时候,可以关闭副本(减少数据同步),暂停搜索服务,或选择在检索请求量谷值区间时间段来完成。因为副本的存在会导致主从之间频繁的进行数据同步,大大增加服务器的资源占用。
- 可通过则设置 index.number_of_replicas 为 0 以加快索引速度。没有副本意味着丢失单个节点可能会导致数据丢失,因此数据保存在其他地方很重要,以便在出现问题时可以重试初始加载。初始加载完成后,可以设置 index.number_of_replicas 改回其原始值。
- max_result_window 参数
分页返回的最大数值,默认值为 10000。通过设定一个合理的阈值,避免初学者分页查询时由于单页数据过大而导致 OOM。
2. 提高写入实时性(不推荐)
在搜索引擎的业务场景下,用户一般并不需要那么高的写入实时性。有时这个延时的过程需要处理很多事情,比如信息需要后台审核。
可以提高 Memory Buffer 的 refresh 操作频率,但是过高的 refresh 会导致频繁 merge segment,会消耗更多堆内存、CPU 的资源。
查询调优
1. 避免单次召回大量数据
搜索引擎最擅长的事情是从海量数据中查询少量相关文档,而非单次检索大量文档。非常不建议动辄查询上万数据。如果有这样的需求,建议使用滚动查询。
2. 避免单个文档过大
硬性限制:
鉴于默认 http.max_content_length 设置为 100MB,Elasticsearch 将拒绝索引任何大于该值的文档。可以增加该特定设置,但 Lucene 仍然有大约 2GB 的限制。
大型文档对网络、内存使用和磁盘造成了更大的压力,即使对于不请求的搜索请求也是如此。
3. 使用 filter 代替 query
query 是要对查询的每个结果计算相关性得分的,而 filter 不会。另外 filter 有相应的缓存机制,可以提高查询效率。
4. 避免深度分页
5. 使用 Keyword 类型
并非所有数值数据都应映射为数值字段数据类型。Elasticsearch 为查询优化数字字段,例如 integeror long。如果不需要范围查找,对于 term 查询而言,keyword 比 integer 性能更好。
参考: