
Zookeeper 从入门到入土⑦:应用场景
1. 数据发布 / 订阅
1.1. 概述
即所谓的配置中⼼,顾名思义就是发布者将数据发布到 ZooKeeper 的⼀个或⼀系列节点上,供订阅者进⾏数据订阅,进⽽达到动态获取数据的目的,实现配置信息的集中式管理和数据的动态更新。
两种设计模式:
- 推(Push)模式:服务端主动将数据更新发送给所有订阅的客户端
- 拉(Pull)模式:由客户端主动发起请求来获取最新数据,通常客户端都采⽤定时进⾏轮询拉取的⽅式
- ZooKeeper 采⽤的是推拉相结合的⽅式:
- 客户端向服务端注册⾃⼰需要关注的节点,⼀旦该节点的数据 发⽣变更,那么服务端就会向相应的客户端发送 Watcher 事件通知。
- 客户端接收到这个消息通知之后, 需要主动到服务端获取最新的数据。
1.2. 配置中心
- 配置获取:应⽤在启动的时候都会主动到 ZooKeeper 服务端上进⾏⼀次配置信息的获取。同时,在指定节点上注册⼀个 Watcher 监听。
- 配置变更:当配置信息发⽣变更,服务端都会实时通知到所有订阅的客户端,从而达到实时获取最新配置信息的目的。
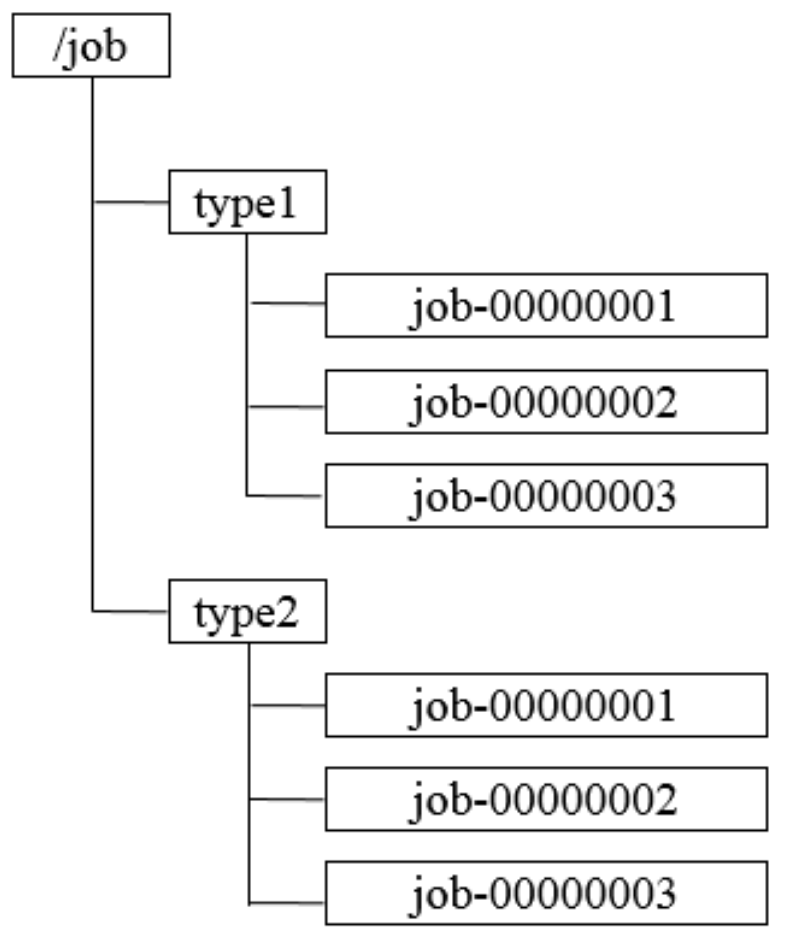
2. 命名服务
通过调⽤ ZooKeeper 节点创建的 API 接⼝可以创建⼀个顺序节点,并且在 API 返回值中会返回这个节点的完整名字。利⽤这个特性,我们就可以借助 ZooKeeper 来⽣成全局唯⼀的 ID
3. 集群管理
我们经常会有类似于如下的需求:
- 如何快速的统计出当前⽣产环境下⼀共有多少台机器
- 如何快速的获取到机器上下线的情况
- 如何实时监控集群中每台主机的运⾏时状态
3.1. 分布式日志收集系统
问题:
如何快速、合理、动态地为每个日志收集器分配对应的⽇志生产机器。
⽇志生产机器和日志收集机器的扩容和缩容
步骤: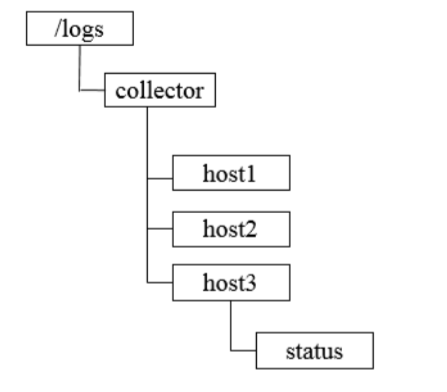
注册收集器: 每个收集机器启动时,都会在总节点下创建⾃⼰的节点,例如
/logs/collector/[Hostname]节点类型为持久节点。若为临时节点,其在会话结束后会被删除,分配的日志生产节点也会消失。
所以可以通过定期维护 status 子节点来表明机器状态
任务分发: 系统根据收集器节点下⼦节点的个数,将所有⽇志生产机器分成对应的若⼲组,然后将分组后的机器列表分别写到这些收集器机器创建的⼦节点上去
状态汇报:
- 每个收集器在创建完节点后,还需要在其⼦节点上创建⼀个⼦节点代表状态,例如
/logs/collector/host1/status。 - 每个收集器需要定期向该节点写⼊⾃⼰的状态信息(⼼跳检测机制),通常写⼊⽇志收集进度信息。⽇志系统根据该节点的最后更新时间来判断对应的收集器是否存活。
- 动态分配: ⽇志系统始终关注
/logs/collector这个节点下所有⼦节点的变更,⼀旦检测到有收集器停⽌汇报或是有新的收集器加⼊,就要开始进⾏任务的重新分配。若采⽤ Watcher 机制,那么通知的消息量的⽹络开销⾮常⼤。
可采⽤⽇志系统主动轮询收集器节点的策略,这样可以节省⽹络流量,但是存在⼀定的延时。
4. Master 选举
作用: 达到只使用一台 Master 处理逻辑,同步至多台 Follower 的效果
原理: ZooKeeper 在分布式高并发下能使节点的创建保证全局唯⼀性,Master 选举可理解成多机器抢分布式锁的过程。
过程:
- Client 集群每天定时会通过 ZooKeeper 来实现 Master 选举
- 在 ZooKeeper 上创建⼀个⽇期节点,例如 2020-11-11。
- Client 集群每天都会定时创建⼀个临时节点,例如
/master_election/2020-1111/binding。创建成功的客户端成为 Master。其他成功创建节点的客户端,都会在节点/master_election/2020-11-11上注册⼀个子节点变更的 Watcher,⽤于监控当前的 Master 机器是否存活。 - ⼀旦发现当前的 Master 挂了,那么其余的客户端将会重新进行 Master 选举。
- Master 会负责进⾏⼀系列的海量数据处理,最终计算得到⼀个数据结果,并将其放置在⼀个内存 / 数据库中。同时,Master 还需要通知集群中其他所有的客户端从这个内存 / 数据库中共享计算结果。
缺点:
负载大,扩展性差。如果有上万个客户端都参与竞选,意味着同时会有上万个写请求。
由于 ZooKeeper 会把写请求转发到 Leader 来处理,再广播到 Follower,所以其写性能不高。
同时一旦 Leader 放弃领导权,ZooKeeper 需要同时通知上万个 Follower,负载较大。
5. 分布式锁
5.1. 排他锁(非公平)
概述: 加锁期间,只允许持有锁的对象对数据进⾏读取和更新操作
实现:
- 定义锁: 通过 ZooKeeper 上的临时数据节点来表示⼀个锁,例如
/exclusive_lock/lock节点就可以被定义为⼀个锁 - 获取锁: 在
/exclusive_lock节点下创建临时⼦节点/exclusive_lock/lock,成功创建的客户端就被认为获取了锁。所有没有获取到锁的客户端就需要到/exclusive_lock节点上注册⼀个⼦节点变更的 Watcher 监听 - 释放锁: 客户端挂掉或者客户端完成业务删除节点。ZooKeeper 会通知所有在
/exclusive_lock节点上注册了⼦节点变更 Watcher 监听的客户端。客户端在接收到通知后,再次重新发起分布式锁获取。
5.2. 排他锁(公平)
实现:
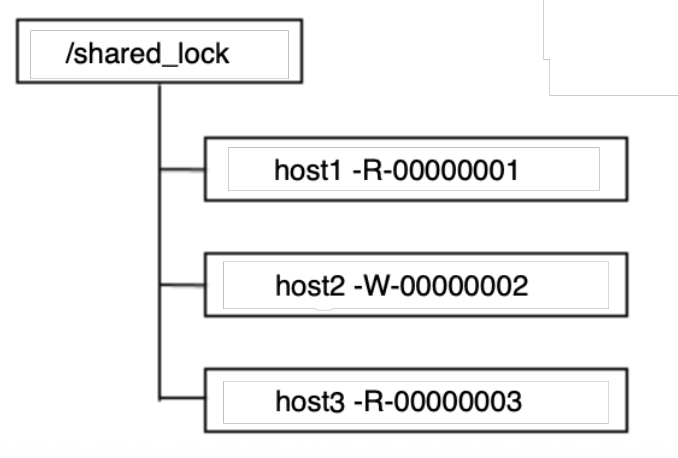
- 定义锁: 通过 ZooKeeper 上的临时数据节点来表示⼀个锁,
/shared_lock/[Hostname]-请求类型-序号的临时顺序节点 - 获取锁: 所有客户端都会到
/shared_lock这个节点下⾯创建⼀个临时顺序节点,然后获取/shared_lock节点下所有⼦节点- 若自己不是序号最小的子节点,那么客户端调用
exist()方法监听前一个节点。 - 接收到 Watcher 通知后,检查自己是不是最小子节点(可能只是前面的未持锁节点宕机了)
- 若自己不是序号最小的子节点,那么客户端调用
- 释放锁: 客户端挂掉或者客户端完成业务删除节点。ZooKeeper 会通知监听的客户端。客户端在接收到通知后,再次重新发起分布式锁获取。
5.3. 共享锁
概述: 加锁期间,只允许所有持锁对象对数据进行读取操作,不允许写操作。
实现: 与公平排他锁类似
- 定义锁: 通过 ZooKeeper 上的临时数据节点来表示⼀个锁,
/shared_lock/[Hostname]-请求类型-序号的临时顺序节点![]()
- 获取锁: 所有客户端都会到
/shared_lock这个节点下⾯创建⼀个临时顺序节点,然后获取/shared_lock节点下所有⼦节点- 对于读请求: 若没有比自己序号小的子节点或所有比自己序号小的⼦节点都是读请求,那么表明自己已经成功获取到共享锁,同时开始执行读取逻辑。否则客户端调用
exist()方法监听前一个 写请求 节点。 - 对于写请求: 若⾃⼰不是序号最小的⼦节点,那么客户端调用
exist()方法监听前一个节点。 - 接收到 Watcher 通知后,重复步骤 1
- 对于读请求: 若没有比自己序号小的子节点或所有比自己序号小的⼦节点都是读请求,那么表明自己已经成功获取到共享锁,同时开始执行读取逻辑。否则客户端调用
- 释放锁: 客户端挂掉或者客户端完成业务删除节点。ZooKeeper 会通知监听的客户端。客户端在接收到通知后,再次重新发起分布式锁获取。
6. 分布式队列
ZooKeeper 不适合作为队列
- 节点大小不足: ZK 有 1MB 的传输限制。 实践中 ZNode 必须相对较小,而队列包含的消息非常大。
- 内存空间不足: ZK 的数据库完全放在内存中。 大量的 Queue 意味着会占用很多的内存空间。
- 启动慢: 如果有很多节点,ZK 启动时相当的慢。 而使用 queue 会导致好多 ZNode. 你需要显著增大 initLimit 和 syncLimit。
- 性能差: 包含成千上万的子节点的 ZNode 时, ZK 的性能变得不好
6.1. FIFO 先入先出队列
和锁的实现相似
- 创建持久顺序节点(由于创建的节点是持久化的,所以不必担心队列消息的丢失问题)
- 获取列表判断是否为最小顺序节点
- 最小:处理逻辑,之后删除
- 不是最小:监听并等待前一个节点
6.2. Barrier 分布式屏障(同步队列)
概述: 特指系统之间的⼀个协调条件,规定了⼀个队列的元素必须都集聚后才能统⼀进⾏安排,否则⼀直等待
应⽤场景: ⼤规模分布式并⾏计算,最终的合并计算需要基于很多并⾏计算的⼦结果来进⾏
过程: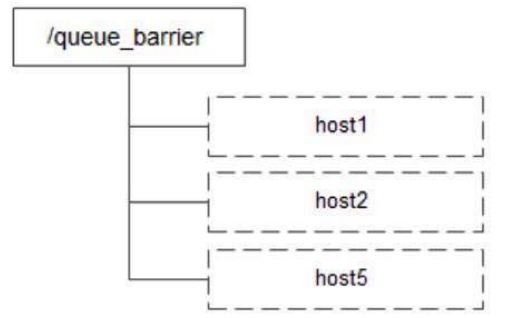
- /queque_barrier 节点值为 10,客户端再该节点下创建子节点
- 获取 /queue_barrier 节点的数据内容:10
- 获取全部节点列表并注册对 /queque_barrier 子节点变化的监听
- 若子节点个数不足 10 个则等待直到个数等于 10
- 若子节点个数等于 10 则进行业务处理