
JVM 从入门到入土 ②:内存加载过程
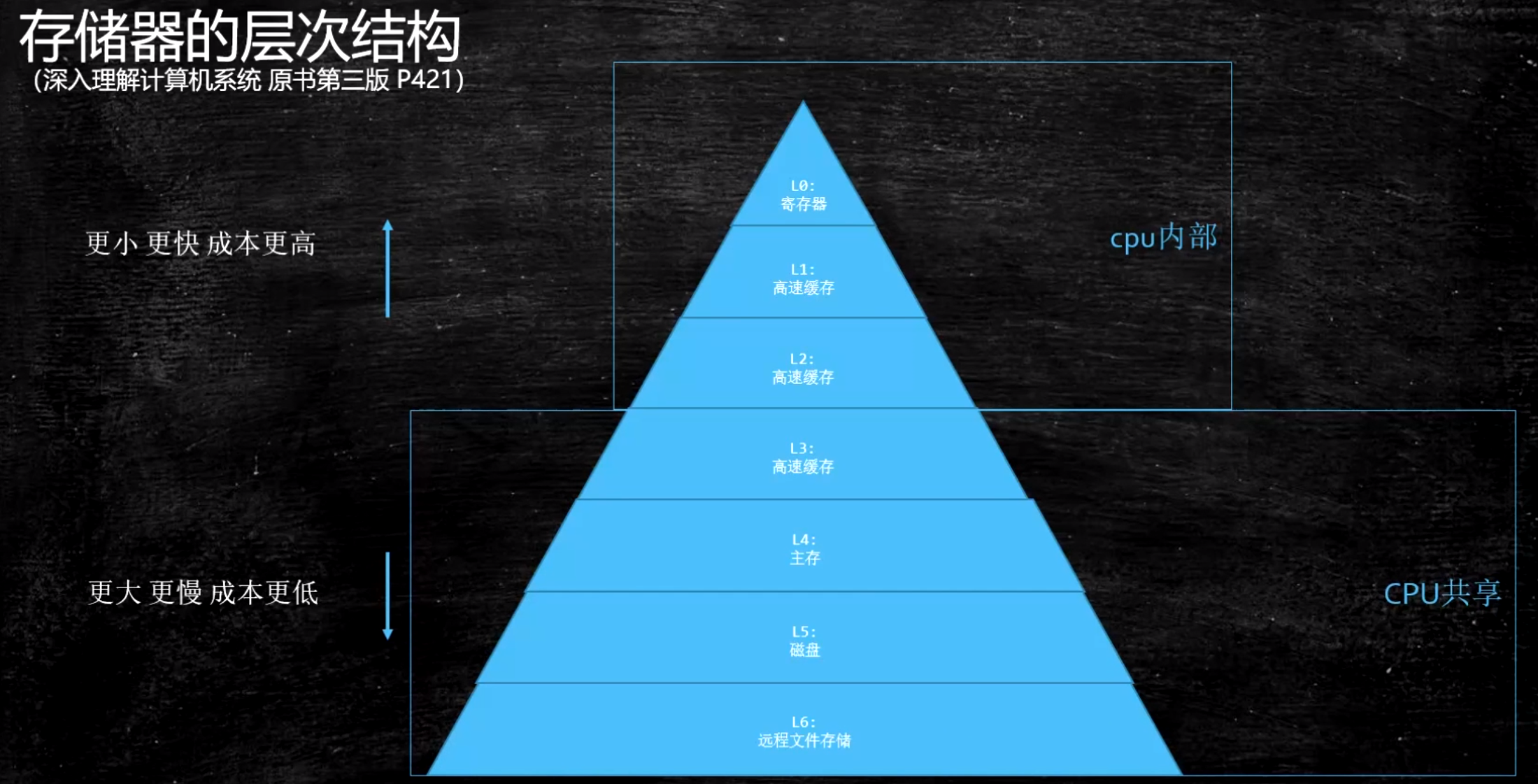
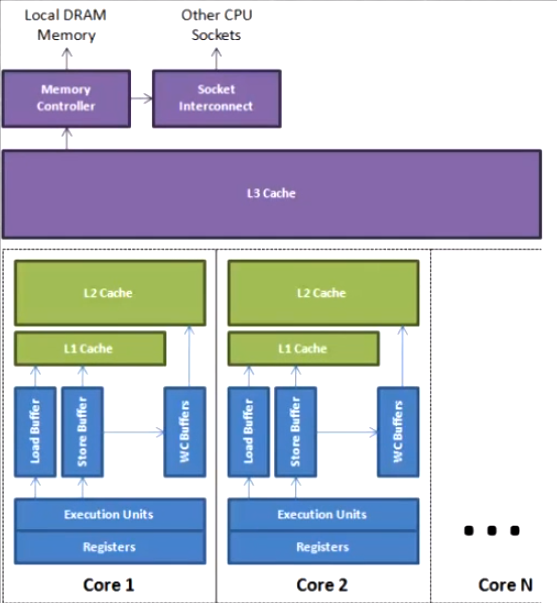
缓存行
内存数据放入高速缓存中时是以缓存行的形式放入的,多数情况把内存中连续的 64 字节的数据作为一个缓存行加入高速缓存,不会只单独放入几个字节的数据
伪共享问题: 位于同一缓存行的两个不同数据,被两个不同 CPU 锁定,产生互相影响的伪共享问题
缓存行对齐
1 | public class CacheLinePadding { |
缓存锁: MESI
【并发编程】MESI–CPU 缓存一致性协议
总线锁: 有些无法被缓存的数据或者跨越多个缓存行的数据还是得使用总线锁
指令重排
验证 JVM/jmm/Disorder.java
现代 cpu 的合并写技术对程序的影响
CPU 为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据,慢 100 倍),去同时执行另一条指令,前提是两条指令没有依赖关系
- 读指令的同时可以执行不影响的其他指令
- 写指令的同时可以进行合并写
WCBuffers(Write Combining Buffers),只能存放 4 字节的数据。用于写指令合并缓存。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59public final class WriteCombining {
private static final int ITERATIONS = Integer.MAX_VALUE;
private static final int ITEMS = 1 << 24;
private static final int MASK = ITEMS - 1;
private static final byte[] arrayA = new byte[ITEMS];
private static final byte[] arrayB = new byte[ITEMS];
private static final byte[] arrayC = new byte[ITEMS];
private static final byte[] arrayD = new byte[ITEMS];
private static final byte[] arrayE = new byte[ITEMS];
private static final byte[] arrayF = new byte[ITEMS];
public static void main(final String[] args) {
for (int i = 1; i <= 3; i++) {
System.out.println(i + " SingleLoop duration (ns) = " + runCaseOne());
System.out.println(i + " SplitLoop duration (ns) = " + runCaseTwo());
}
}
public static long runCaseOne() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
public static long runCaseTwo() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
}
i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
}
如何保证不重排:
- CPU 内存屏障(硬件方面实现):Inter X86
- sfence:在 sfence 指令前的写操作必须在 sfence 指令后的写操作前完成
- lfence:在 lfence 指令前的读操作必须在 lfence 指令后的读操作前完成
- mfence:在 mfence 指令前的写操作必须在 mfence 指令后的读操作前完成
- CPU lock 原子汇编指令(硬件方面实现):Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个 CPU
- JVM 规范(JSR 133):依赖于硬件实现
LoadLoad 屏障:
保证读操作 Load1 先于读操作 Load2 执行1
2
3Load1 操作
LoadLoad 屏障
Load2 操作StoreStore 屏障:
保证写操作 Store1 先于写操作 Store2 执行
1 | Store1 操作 |
LoadStore 屏障:
保证读操作 Load1 先于写操作 Store2 执行1
2
3Load1 操作
LoadStore 屏障
Store2 操作StoreLoad 屏障:
保证写操作 Store1 先于读操作 Load2 执行1
2
3Store1 操作
StoreLoad 屏障
Load2 操作
volatile 实现细节
字节码层面:
ACC_VOLATILE编码JVM 层面:
写操作
1
2
3StoreStore 屏障
volatile 写操作
StoreLoad 屏障读操作
1
2
3LoadLoad 屏障
volatile 读操作
LoadStore 屏障OS 和硬件层面:
volatile 与 lock 前缀指令
synchronized 实现细节
字节码层面
ACC_SYNCHRONIZED1
2
3
4
5
6
7
8; 加锁
monitorenter
...
; 释放锁
monitorexit
...
; 异常后释放锁
monitorexitJVM 层面
C C++ 调用了操作系统提供的同步机制OS 和硬件层面
X86 : lock cmpxchg / xxx
Java 使用字节码和汇编语言同步分析 volatile,synchronized 的底层实现
happens-before 原则
